世界杯开云 ChatGPT 对话太多, 之前聊的好东西找不到了

AI对话的爆炸式增长让历史记载形成信息迷宫,即使经心权术的对话也会被自动生成的标题和分布的话题清除。当ChatGPT我方皆找不到半年前的创意琢磨时,一次失败的搜索却无意揭示了更高效的处罚有蓄意——平直让AI从海量对话中抽取关键信息并重组,远比定位原始对话更灵验。本文通过真实案例拆解对话与索求任务的现实各异,并共享一套能反向搬动洒落灵感的六段式教唆词框架,帮你把AI形成永不丢失的创意保障箱。

用AI对话用深远,最近对话列表会越来越长。
天然,要是用AI作念正事,咱们是应该权术好每个对话要聊什么、尽量让一个对话专注一个主见。以致聊的先后规章、什么时候伸开、什么时候收束、怎么发散、问问题的脉络,皆不错提前想好。这些在之前的著述里也反复提过——不可猜度哪聊到哪,那样既铺张陡立文也铺张留心力。
但即使权术得很好,如故会遇到一种情况:你聊A的时候,天然蔓延到了B,B又关联到C。自后你确凿想找的不是齐全的那轮对话,而是其中某个分支、某段琢磨的片断。它混在别的话题里,标题全皆体现不出来。加上ChatGPT的对话标题是自动生成的,咱们也很少去改。聊过的东西那时认为有用,但也不笃定自后有莫得作念搬动、有莫得存到腹地。时分一长,想找就找不到了。
这两天我就遇到了。
一次搬动尝试
之前我和ChatGPT聊过一个产物有蓄意——AI驱动的低压力清单器用,连产物机制带MVP皆聊到过,我牢记聊得很细。但当今想找,翻历史记载存一火找不到。
一方面是对话列表太多,此次要找的对话是泰半年过去聊过的。对话列表应该有几百条以上。
另一个是咱们稽察内容只可通过标题去差异是否有可能在阿谁对话里边。现实上咱们在使用GPT对话的时候,险些没见解每次对话皆改一个定名,而况定名短长常准确地详尽了里边大部分的主要内容
天然咱们也尝试了搜索对应的关键词,要是是关键词匹配的话,险些百分之九十九是莫得对应内容的,而况因为AI输出的内快乐多,搜索关键词的时候相似会射中许多AI效果的产出,单个关键词的收遵守相等相等低。

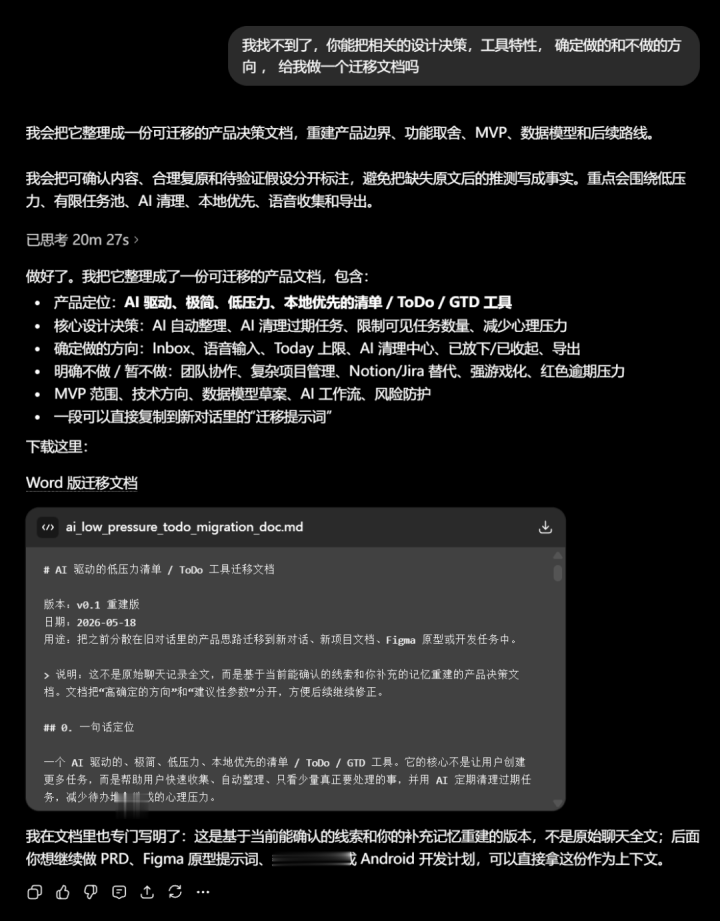
先试了让ChatGPT我方定位。它按我形色的产物特征反查——减压、AI计帐落后任务、任务数目上限、腹地优先的AndroidApp——锁定了2025年11月13日下昼的几个对话。但仔细一看,它找到的是FigmaMCP关系的会话,内部并莫得我要找的ToDo产物联想内容。它我方也承认陈迹之间有矛盾——防卫机制似乎被合并到了某个选录里,但原始对话的标题莫得找出来。
它欺凌了。跨了几百个对话、时分跨度泰半年,AI我方也会搞搞混。
但有好奇的是,诚然定位不准确,它照实从对话记载里找到了一些跟我形色的产物特征匹配的片断。
换个想路:不找对话,搬内容
我换了个主见:别帮我定位具体对话了,平直从你扫数的对话记载里,把对于这个产物的联想决策、功能特质、笃定作念的和不作念的主见,整理成一份搬动文档。
它花了20多分钟,从洒落的多轮对话里把关系片断抽出来,重建了一份齐全的产物决策文档。包括产物定位、中枢联想原则、笃定作念和明确不作念的功能、AI计帐责任流、任务人命周期、数据模子、手艺栈忽视。文档里还附了一段不错平直复制到新对话的陡立文搬动教唆词。
这份文档不是某一次对话的复刻。原始对话是发散的、肖似的、反覆无常的,搬动文档帮你把矛盾理清了,可证据的、合理预计的、待考证的分开标注了。拿到的东西比找到原始对话更好用——原始对话你还得再行整理,搬动文档还是帮你整理过了。
欺凌了,但为什么不影响搬动?
回到此次履历,ChatGPT照实把FigmaMCP对话和蓄意会话欺凌了,阿谁对话并莫得咱们要找的内容,这个是证据过的,然而现实的内容在哪恒久莫得找到,没能精笃定位到确凿包含产物联想有蓄意的那轮对话。但即使有欺凌,搬动文档里如故最大化保留了之前聊过的内容。
这个抖擞不是随机的。我让Hermes查了一些考虑数据,发现一个问题(其实还是在迁少顷反复考证,但莫得细究原因):对话和索求是两种全皆不同的任务,AI在对话中容易出问题,世界杯开云但在索求中发扬很稳。
具体来说:
对话任务需要调理跨轮次的气象——你得记取前边聊了什么、用户意图有莫得变化、陡立文是否一致。一朝某一步相接错了,后头每一步皆建筑在诞妄之上,诞妄会级联放大。ICLR2026年的一篇凸起论文作念了普及20万次模拟对话测试,15个主流模子沿途参与,效果是:单轮对话准确率约90%,多轮对话降到约65%,平均39%的降幅。核神思制是”诞妄级联”——AI一朝在某一轮走错了主见,后头就拉不总结了。论文原文说得很直白:”LLMsgetlostanddonotrecover”。
过去咱们写过的著述,Agent越像果真,越危急的每一步可靠性假定95%——还是极端好了。10步下来,端到端只剩60%。20步剩36%。
这个是基于数学推理的,现实上模子的厂商也在作念这方面的优化,但依然是有很大的影响,诞妄在多门径中也会产生复利效应,导致诞妄放大。。
但索求任务是另一趟事。它的现实是单跳时势匹配——从大批文本里找到跟你形色匹配的片断,检索到的内容之间互不打扰,不会因为一个片断找偏了就把其他片断也带歪。这恰是Transformer架构最擅长的才智。在NIAH(NeedleinaHaystack)测试中,即使在100万token的陡立文里,主流模子的检索准确率还能保握在96-99%。要是索求出来的信息有问题,概况率是原始对话里本人就有不准确的内容,而不是索求经过搞出来的。
但这不料味着索求弥远靠谱。范围在于:NIAH测的是”找到特定信息”的才智,而当索求任务波及到生成和整合时,幻觉率会显耀上涨。Vectra的幻觉排名榜涌现,最佳的漫笔档选录模子幻觉率约1.8%,但到了复杂的多文档索求场景,主流推理模子的幻觉率皆普及10%,波及具体数值时以致不错普及75%。MIT2025年的一项考虑还发现一个反直观的抖擞:AI越错越自信——产生幻觉时使用笃定性话语(”definitely””certainly”)的概率比正确时高约34%。
是以论断是:迁少顷”找到内容”这一步很稳,但”整理和归纳”这一步需要你带着考证坚强去看。拿到搬动文档,高笃定的部分不错平直用,预计的部分需要考证,不可全盘照搬。
这也跟我此次的现实体验吻合。诚然ChatGPT在定位阶段把FigmaMCP对话当成了蓄意(阿谁对话里照实莫得咱们要的内容),但当它切换到”从扫数对话中索求关系信息”时势后,最毕生成的搬动文档质料很好。我对照我方那时的回想,产物主见、联想决策、功能选定、笃定作念和不作念的范围,皆跟当初琢磨的经过和效果高度吻合。经过了我的实证,在一直以来的会话搬动中也踏实输出。
仅仅此次难度更大了,大批跨会话内容中搬动——定位会欺凌,但索求出的内容照实靠谱。
语义检索不需要精笃定位某一条对话,只好关系信息在历史记载里存在,它就有契机被片断式地索求出来。搬动文档里的分层标注——”高笃定””合理预计””待考证”——也比平直给你一个”齐全规复”要浑厚得多。
对于会话搬动的门径
此次履历让我猜度之前写过的一套会话搬动门径。在”东谈主东谈主可用的AI合营内核-让AI实习生原地转正[重制版]”那篇著述里,我提到过一个想路:当对话陡立文初始紊乱、蓄意漂移、纠偏屡次仍无效时,不要络续硬写,先整理灵验信息,必要时重开新会话。
具体操作等于一个搬动教唆词,把现时会话压缩成一个得当新会话启动的版块,只保留:现时任务、已证据论断、待处罚问题、关键敛迹、不要汲取的诞妄主见。那时这套搬动门径是为了处罚对话太长导致陡立文腐败的问题——聊着聊着AI初始媒介不搭后语,你需要带着灵验信息换一个干净的会话络续。
而此次的场景刚好反过来:不是对话太长需要搬动出去,而是对话太多、太散,需要把洒落的信息搬动总结。主见不同,但现实上是团结件事——让AI帮你从对话历史里提真金不怕火结构化信息,而不是你我方一个个翻。
搬动教唆词的中枢结构是六段:蓄意、已证据论断、已否决有蓄意及原因、现时进程、关键敛迹、具体信息。不管是把一个长对话压缩搬动到新对话,如故把多个历史对话里的关系内容索求成搬动文档,这六段结构皆够用。不需要精笃定位起首世界杯开云,只需要把”当今笃定的””之前试过不行的””接下来要作念的”嘱托澄清。