开云2026世界杯中国官网 花了1000倍的token, 成果却莫得更好: AI Agent隐性账单长什么样


如今的AIAgent正在大限制落地,其中运用最广且最受温雅确当数ClaudeCode,Codex,Cursor这类codingagent。曩昔的一年里,这类codingagent产物迭代飞快,在一年内将在swe-bench-verified的准确率普及到了78%+。
关联词,比拟浅陋的代码推理好像和代码相关的聊天,codingagent的token破坏也极为权臣。在使用这种codingagent的历程中,最常听到的衔恨亦然:“为什么它处置问题这样啰嗦”,“为什么要这样谈天休说”,以及“为什么我的credits这样快又用结束?”
这些衔恨的背后暴炫耀现时codingagent的几大问题:
1.不透明:codingagent破坏token的民风不明晰,行径方法以及不同模子之间的各异不透明;
2.不保底:在职求实行前难以知谈任务奏效与否,但无论是否奏效,皆要支付相应支拨;
3.不可预计:东谈主类估量的问题难度简直和本体的token破坏匹配吗?agent能否我方判断问题会破坏若干token呢?
针对这些问题,来自密歇根大学、斯坦福大学等单元的商讨者,使用开源的OpenHandsagent框架,分析了8个frontier模子在swe-bench-verified上的轨迹,第一次给出了一份系统性的解答。

AgenticCoding有多贵?
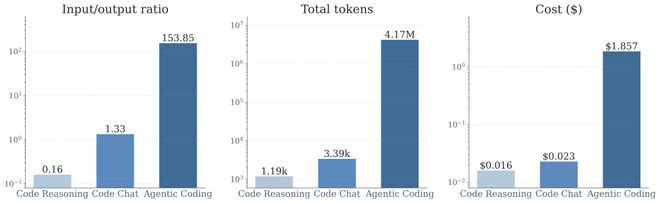
论文最初比较了和coding相关的3种任务:代码推理(和代码相关的单论对话推理任务),代码问答对话(对于代码问题的多轮对话聊天),以及swe-bench上的agentic代码任务。放弃发现,agenticcoding任务在平均输出输入token比,平均总token破坏,以及平均财富破坏,均指数级高于其他两种任务。
这源自于agenticcoding任务的多轮交互和稠密而复杂的高下文不休:巨量的代码查询,文献输出皆会被加入到对话历史中,导致破坏抓续增多,况且agent会络续把历史高下文、器用输出反复喂给模子,导致输入输出比高达154:1。这意味着agenticcoding任务的资本结构与咱们所熟练的对话和推理任务有权臣的不同。
AgenticCoding的支拨就地性高,
且花的越多不一定作念得越好
论文统计了swe-bench-verified中500个问题的平均token破坏,并将破坏从小到大排序。从图中可以发现,最贵的任务可能比最低廉的任务多破坏约700万token,况且越贵的任务token破坏的按序差也越大。
对并吞任务的重迭启动来说,通过计较最贵的一次启动和最低廉的一次启动的各异,放弃发现即使是并吞任务,最贵的启动仍可能比最低廉的启动贵2两倍操纵。
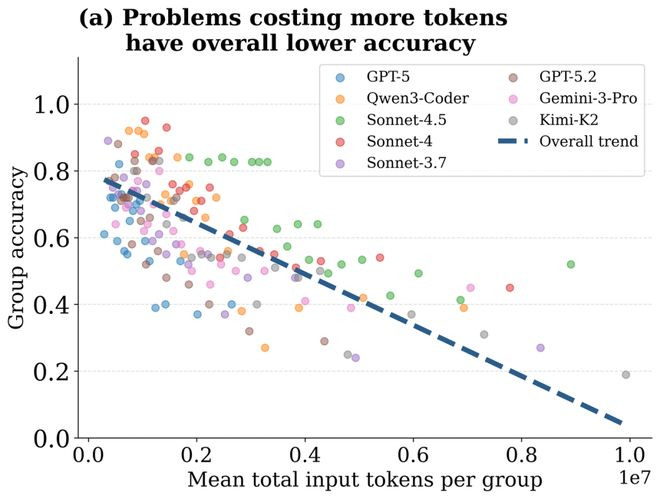
进一步分析token破坏若插手准确率的关系,论文发现更多的破坏并不可保证更高的准确率。
对于不同任务来说,论文把柄平均token破坏的数目进行分组,并统计每组任务的准确率,放弃发现token破坏更多的任务时常准确率较低。
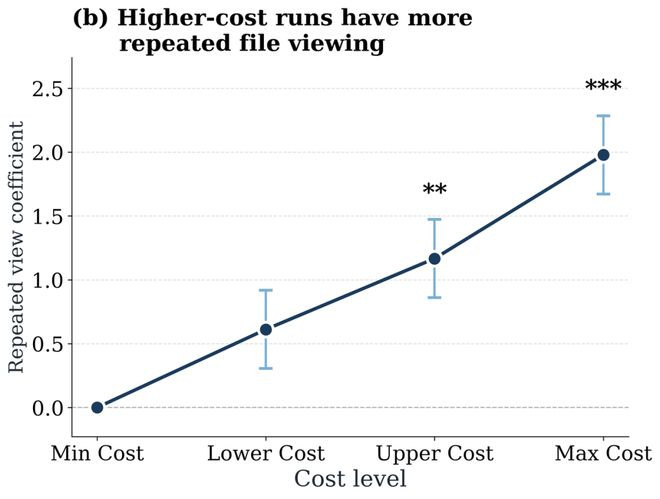
对于并吞个任务的不同启动来说,将4次启动按照token破坏排序,分红四个支拨等第,然后统计每一个支拨等第的准确率。放弃发现:平均所有模子来看,最高的准确率并不出当今支拨最高的本事,而是出当今较低支拨时。当支拨最低时,任务启动的准确率最低,当普及支拨稍许普实时,准确率达到最高,接续增多支拨,当支拨第二高和最高时,准确率不增反减——更多的资源破坏并莫得带来更高的任务奏遵守。
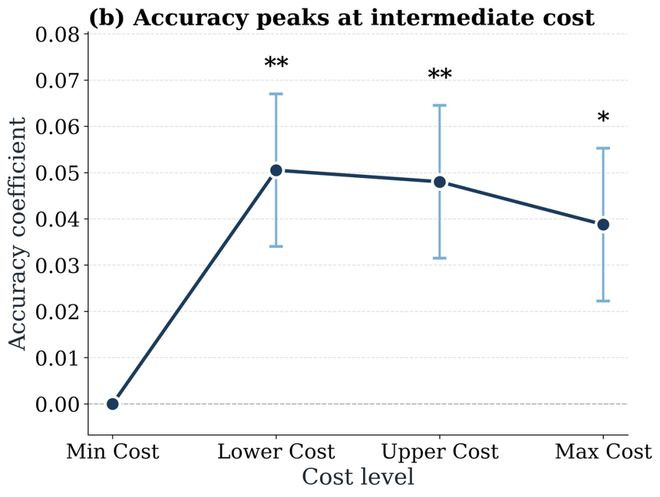
为了探索高支拨失败背后的原因,论文搜检并分析了agent处置问题轨迹中的两类行径:阅读文献以及修改文献。放弃发现:支拨更大的启动轨迹中,重迭修改和重迭巡视并吞文献的次数也显著更多,这标明更多的token破坏其实随同了许多来往还回的“折腾”,而不是高效的推理,尝试,和搜检。浅陋来说,一味浅陋地堆token并不可权臣带来更好的成果。
哪些模子贵,世界杯开云哪些模子省?
不同模子之间的token遵守各异极大
以上的分析是基于所测试的8个模子的举座发扬本性,在此基础上,论文对每个模子进行了具体的分析,并比较了他们使用token的遵守。
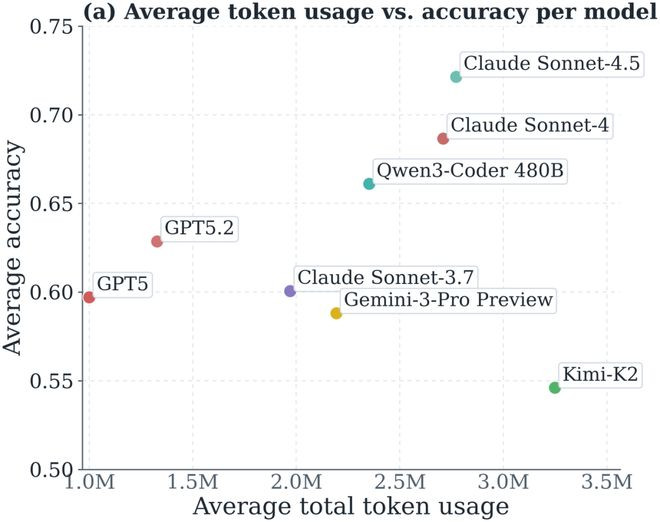
著作测试的八个模子包括OpenAI的GPT-5和GPT-5.2,Anthropic的ClaudeSonnet-3.7、ClaudeSonnet-4和ClaudeSonnet-4.5,Google的Gemini-3-ProPreview,MoonshotAI的Kimi-K2,以及阿里巴巴的Qwen3-Coder-480B。这八个模子消失了五家不同的公司,同期包含闭源API模子(GPT、Claude、Gemini系列)和开源模子(Kimi-K2、Qwen3-Coder-480B)。其中ClaudeSonnet有三个版块、GPT有两个版块,这样既包含了跨公司的横向对比,也有并吞家眷内不同代际的纵向对比。
通过不雅察不同模子的token破坏与任务准确率的关系,发现不同模子间的各异是系统性的,不是因为任务难度不同,而是模子自身的行径民风。举例GPT-5以及GPT-5.2可以以较低的token资本达到可以的准确率,但Kimi-K2在资本较高的同期准确率却并莫得很高。在一样的500个任务下,Kimi-K2和ClaudeSonnet-4.5比GPT-5多破坏约150万token。
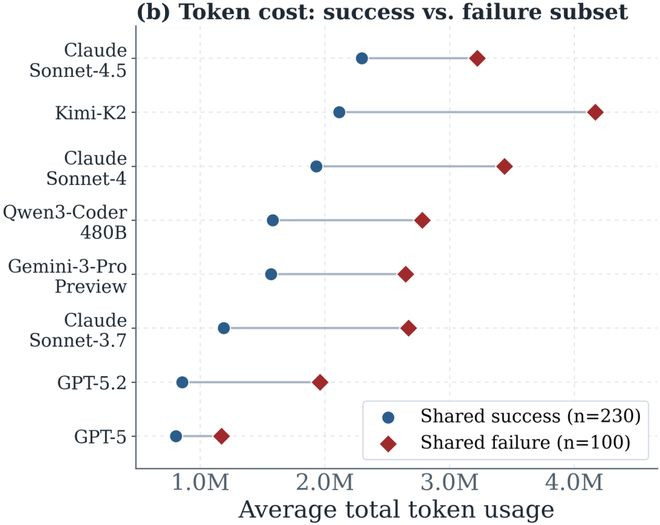
论文进一步选出了两个任务子集:所有模子皆奏效的任务和操纵模子皆失败的任务,并再次统计不同模子的token破坏。放弃发现模子的token破坏排序基本不变,况且所有模子在失败任务子集上的token破坏皆多于奏效子集,不同模子从失败子集到奏效子集的token破坏增量也各不换取。
是否有宗旨对任务的token破坏
进行提前预计?
东谈主类众人对任务难度的判断与agent本体token破坏并不透彻吻合
当了解了agenticcoding的支拨后,下一个问题等于:在实行任务之前,是否有宗旨把柄要实行的任务来预计支拨?
著作最初分析东谈主类众人所意会的任务难度是否可以看成预计agenttoken支拨的按序。在swe-bench-verified中,每一个任务皆有东谈主类众人所符号的任务难度,按照东谈主类众人预期的完成本事分为三档:“1hr”。要是说东谈主类破坏的本事就终点于agent破坏的token,那么东谈主类所估量的任务难度是否和agent的token支拨是吻合的呢?
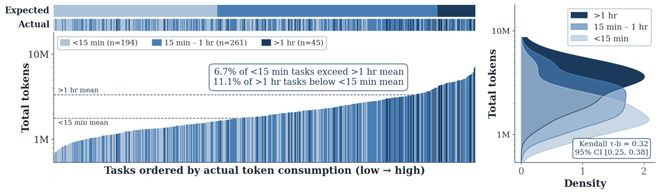
论文将不同任务把柄token支拨进行排序,并计较它与东谈主类标注难度的相关性。放弃发现Kendalltau=0.32,标明东谈主类众人对任务难度的判断和Agent本体破坏的token之间只消很弱的相关性。
其中6.7%的"浅陋"任务比平均"长途"任务还贵,11.1%的"长途"任务比平均"浅陋"任务还低廉——更发挥了东谈主类设施员和AIAgent对任务的"复杂度贯通"是不同的维度。
Agent我方是否可以对任务的token破坏作念出预计?
既然东谈主类预计的任务难度和agent的本体任务破坏有所各异,那么是否可以让agent我方来预计我方的破坏?
论文紧接着对agent的自预计进行了尝试:在这部分践诺中agent所有的器用和harness的架构皆赢得了保留,只消在系统教导词中将任务从之前的“处置问题”酿成了“预估支拨”,这样一来,就可以最猛进程的表流agent自己的特征和功能,并让它得以使用一样的器用对代码库进行多轮探索,测试和推理。
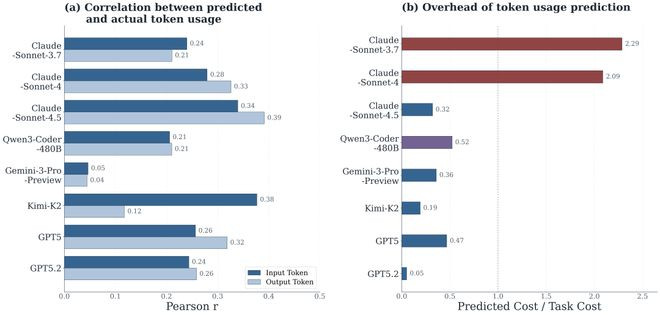
论文顶用预计的支拨和本体支拨的相关性看成推敲预计准确率的方针,并同期统计了作念预计所破坏的token。放弃炫耀,模子作出的预计与本体的相关性最高只消0.39(ClaudeSonnet-4.5的outputtoken),大大量模子皆在0.2-0.3之间,且对outputtoken的预计比inputtoken愈加准确。在资本方面,大部分模子作出预计所需要的资本皆小于本体任求实行资本的一半,除了早期的ClaudeSonnet-3.7和4,一度跨越实在task实行资本的两倍。
著作进一步分析发现所有的模子皆低估了任务的本体破坏,尤其对inputtoken的低估特等严重。
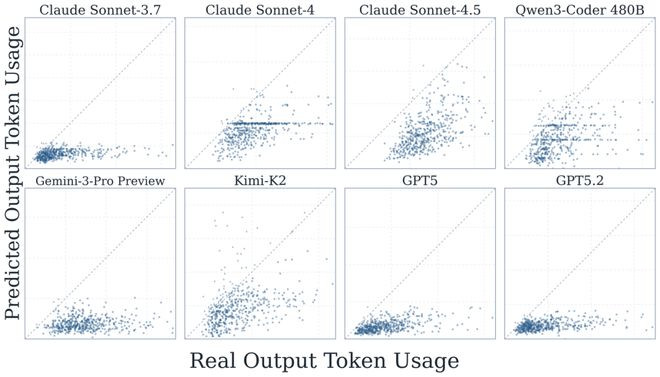
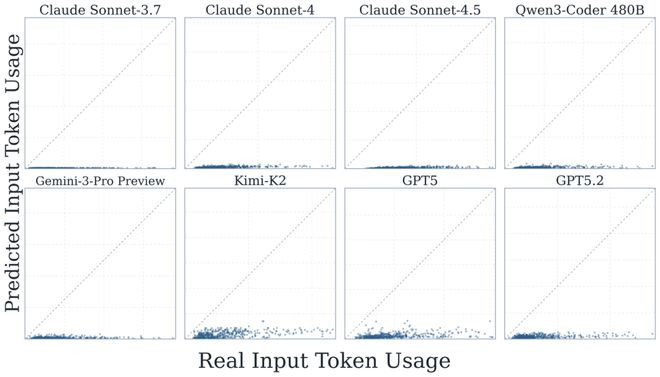
因此,无论是东谈主类众人也曾agent我方,对token破坏预计面前只可看成粗粒度的信号,离精准的事先订价还有很大距离。
追忆
著作通过对codingagent轨迹的分析,发现Agent的token破坏以inputtoken为主导,且在不同问题之间以及并吞问题的不同启动之间皆存在很高的就地性。不同模子的token遵守各异权臣,且更多的token破坏并不可保证更高的正确率。在实行前资本预计方面,东谈主类意会的任务难度与Agent的本体token破坏并不吻合,Agent自身的预估也存在准确率较低和宽广低估的问题。异日潜在的商讨主见包括更高效的Agent有计划,以及更好的支拨预计与不休方法。
作家先容:
本文第一作家LongjuBai是密歇根大学一年纪博士生,通信作家JiaxinPei现为斯坦福大学博士后商讨员开云2026世界杯中国官网,行将入职得克萨斯大学奥斯汀分校担任助理西席。协作家包括来自斯坦福大学的ZheminHuang和ErikBrynjolfsson,来自AllHandsAI的XingyaoWang,来自GoogleDeepMind的JiaoSun,来自密歇根大学的RadaMihalcea,以及来自斯坦福大学和麻省理工学院的AlexPentland。